前段时间在看零知识证明的基础理论以及GPU可以进行性能优化的点。这篇文章总结一下CUDA开发的入门知识和cuda-fixnum源代码导读。有需要通过Nvidia的GPU实现性能优化的小伙伴,可以看看。欢迎大家留言交流。
01CUDA开发基本概念
相对CPU,GPU在通用并行计算方面有很强的优势。Nvidia给出了一组对比数据:
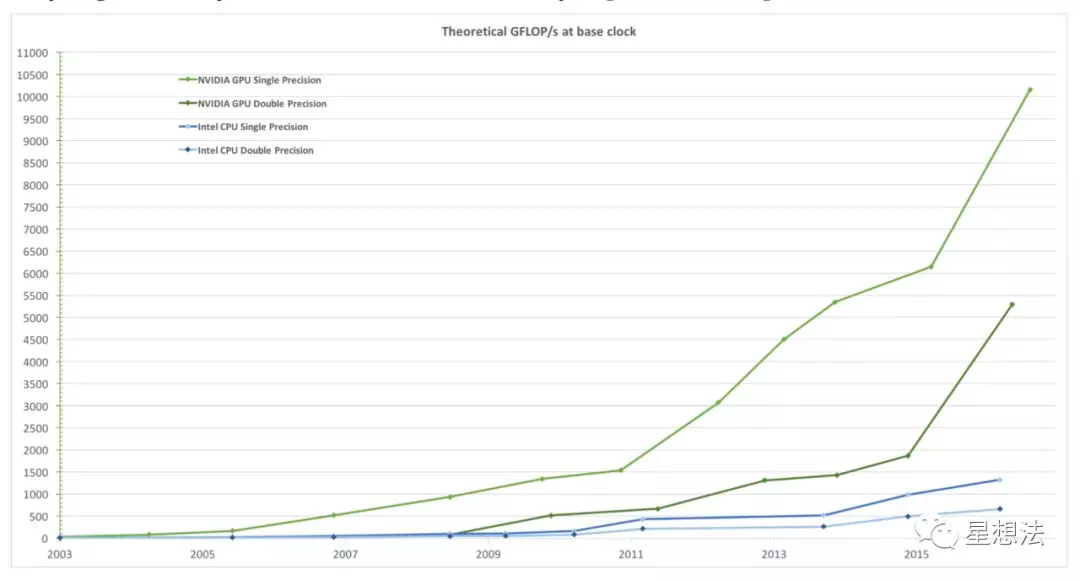
从浮点计算能力来看,Nvidia的GPU性能比Intel的CPU高出10多倍。
GPU的物理模块
整个GPU主要由两大部分组成:显存和SM。
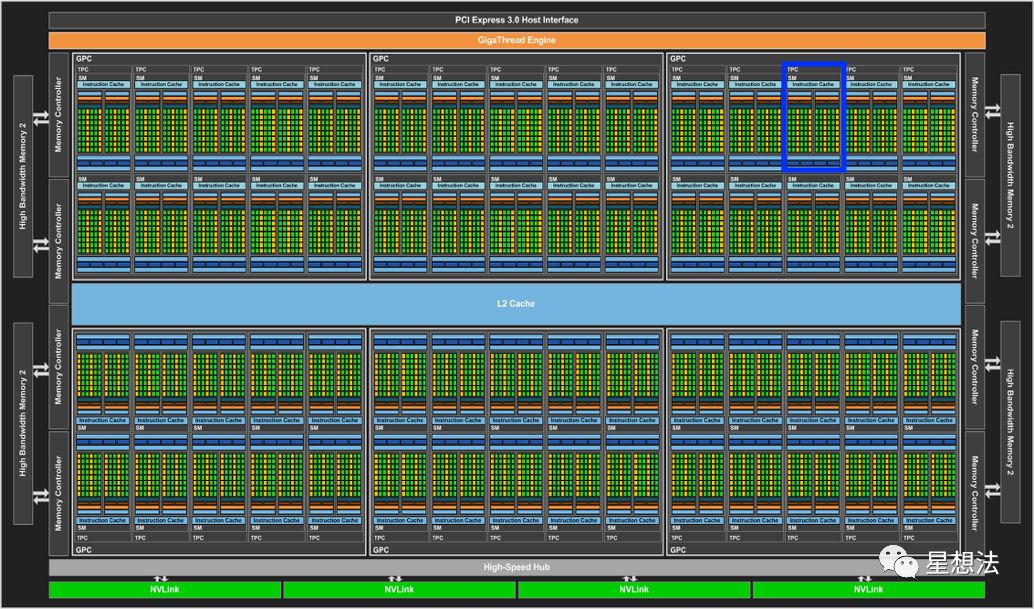
SM - Streaming Multiprocessor。上图中用蓝色的框指明一个SM。整张GPU有许多SM组成。
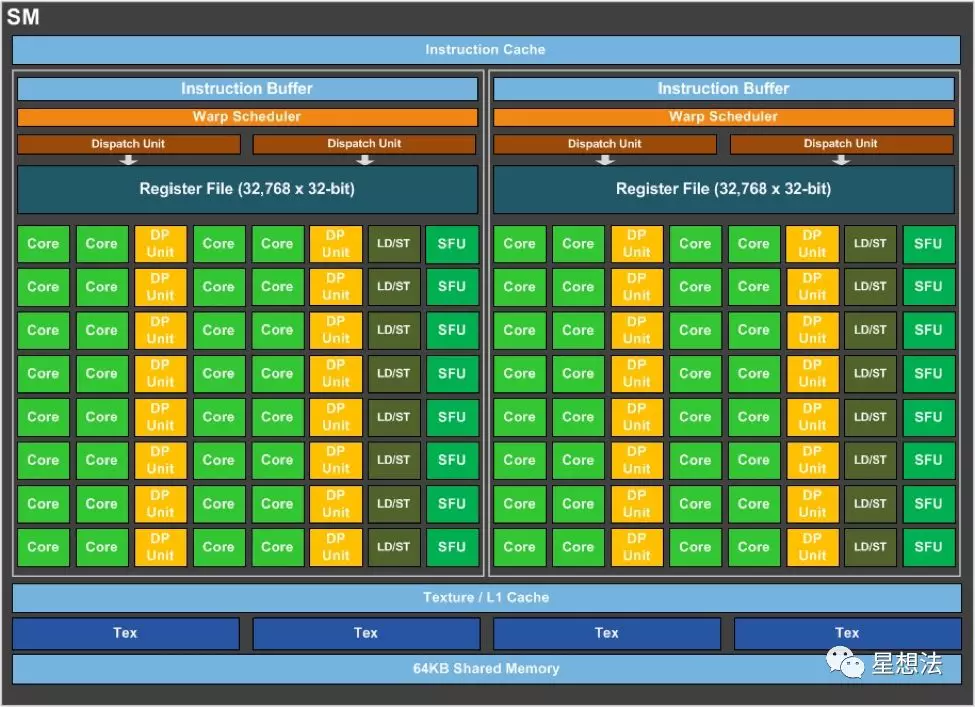
一个SM,由很多“核”组成。一个个的这些“核”,称为SP - Scalar Processor。SP由逻辑处理单元,分支预测单元等组成。
GPU的线程执行模型
Nvidia的官方文档比较清晰的阐述了CUDA开发的软件相关的基本概念:https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html。
一组在GPU上并行执行的函数,称为Kernel。一个Kernel的所有线程,分为Grid,Block,Thread三层逻辑关系。
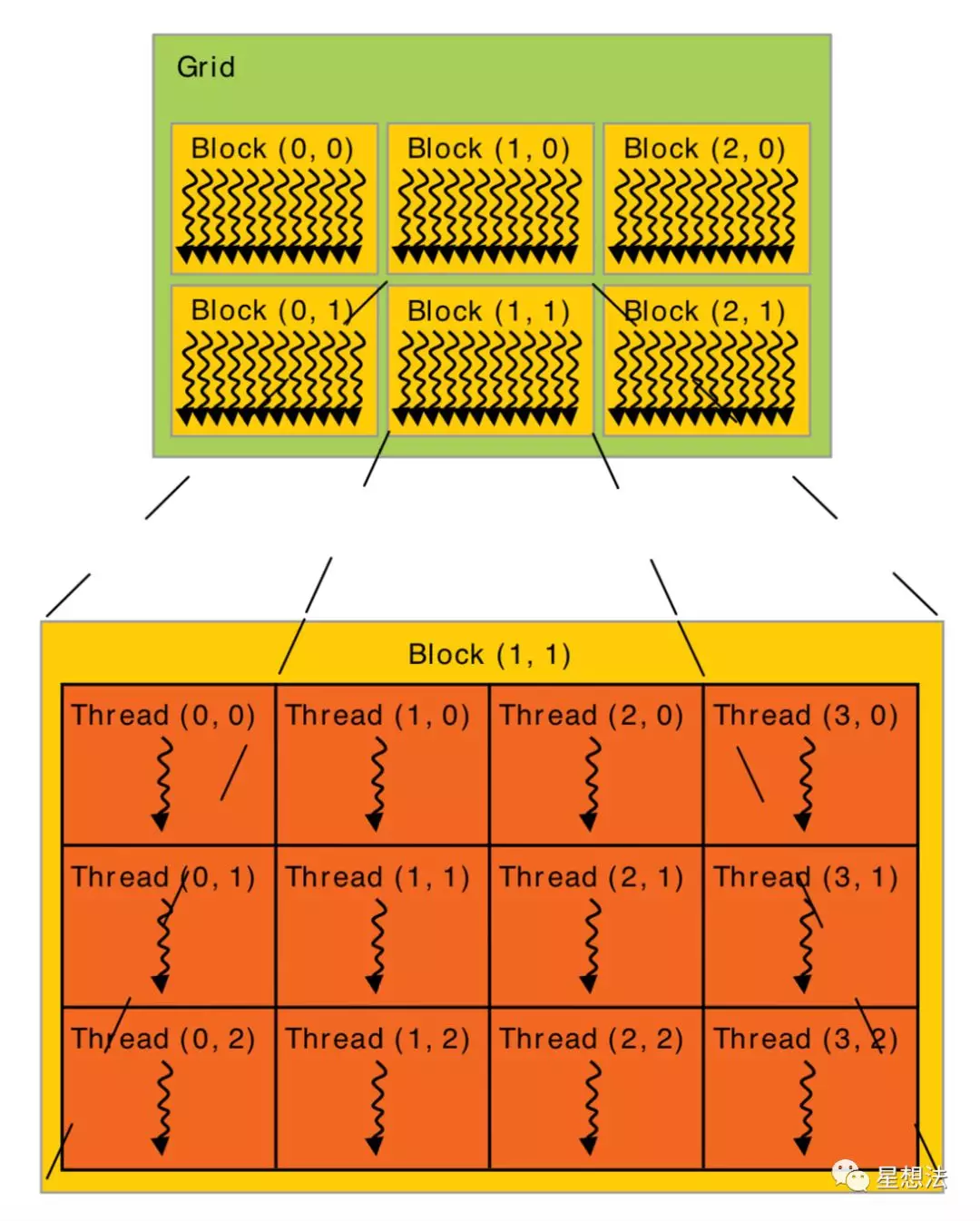
一个Grid由多个Block组成,一个Block也是由多个Thread组成。GPU的线程执行模型和硬件模块之间的对应关系如下图:

所有的Thread都在SP上执行。Block中的所有Thread都是由SM来执行。
SIMT和Warp
SIMT - Single Instruction Multiple Thread,指的是一个指令在多个Thread上执行。一个SIMT指令通过一个Warp(32个Thread)执行。一个Block中的所有Thread,分成多个Warp在SM执行。

内存模型
所有的Block Thread共享Global内存。一个Block内的Thread共享Shared内存。一个Thread内有寄存器,本地内存以及缓存。
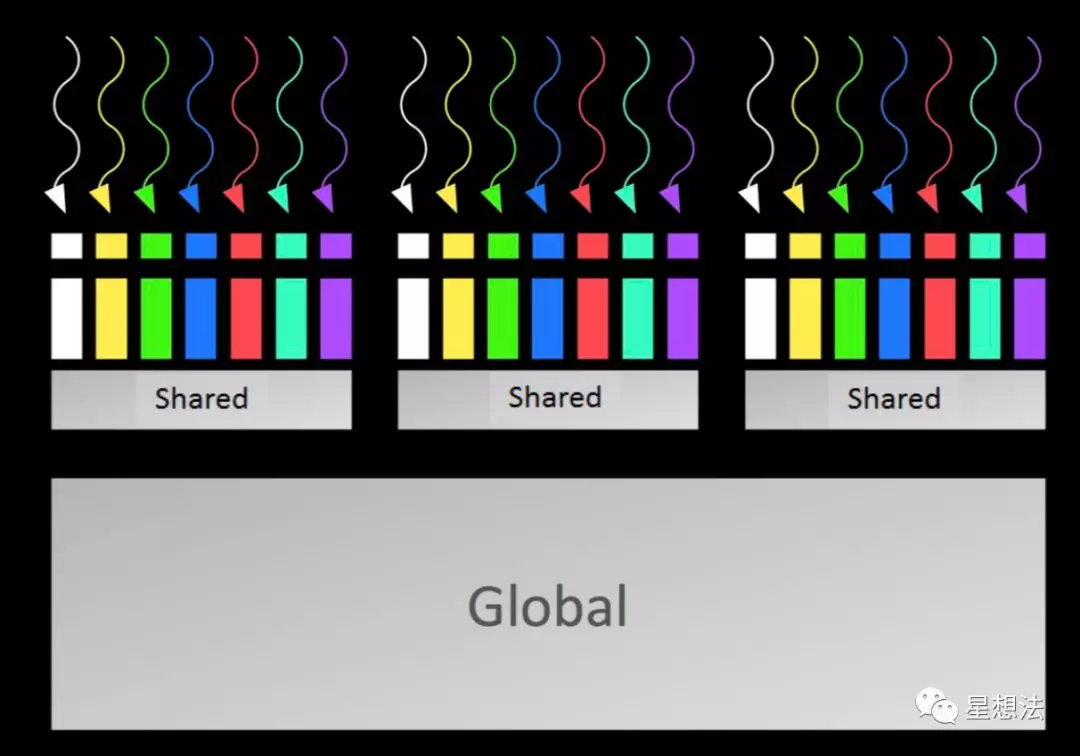
Unified Memory
GPU和CPU之间需要共享数据时,Unified Memory提供了统一的地址空间。
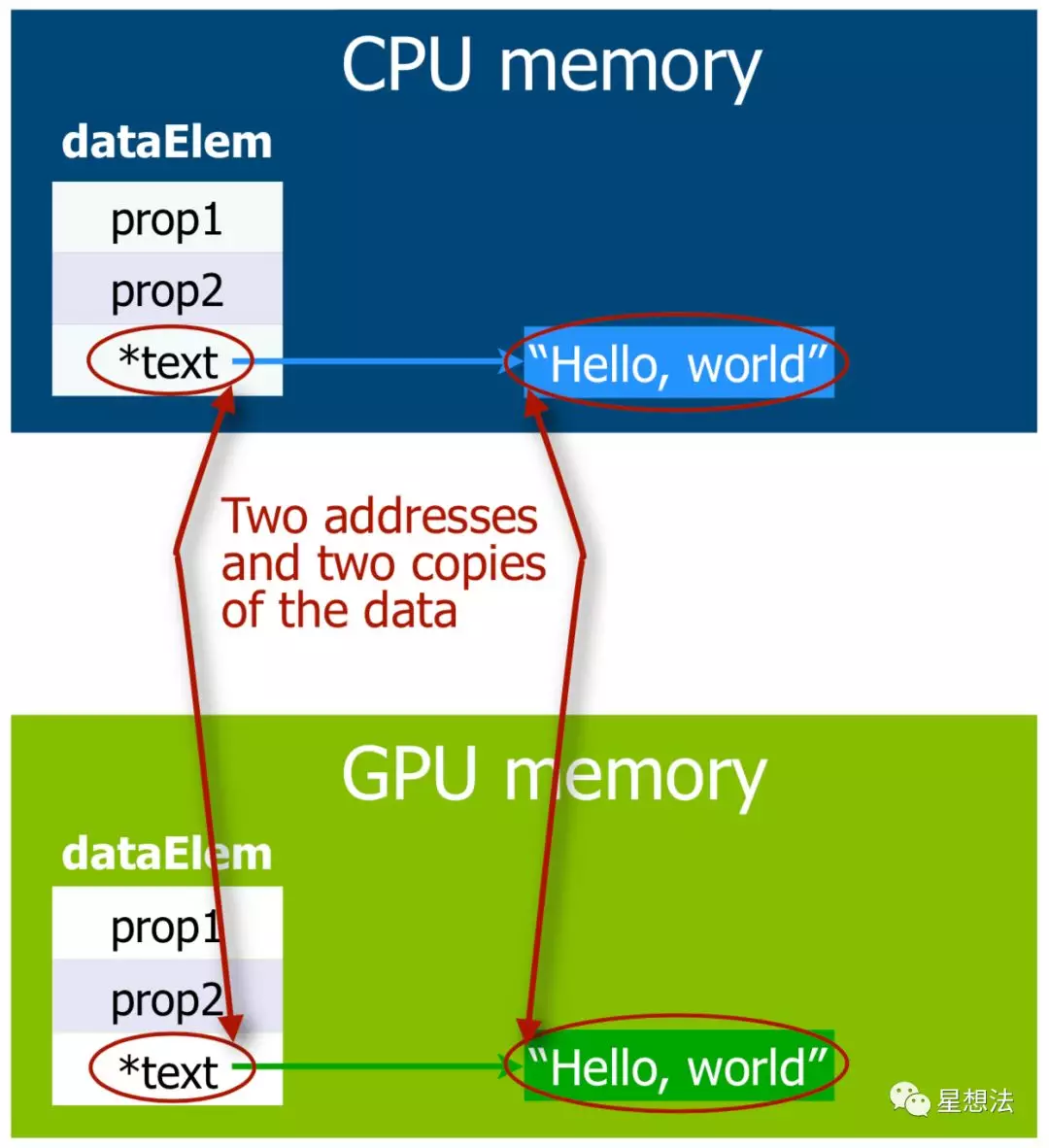
在Unified Memory问世之前(CUDA 6.0之前),在GPU和CPU之间共享数据非常繁琐,需要内存的多次Deep Copy (调用cudaMalloc , cudaMemcpy等函数)。
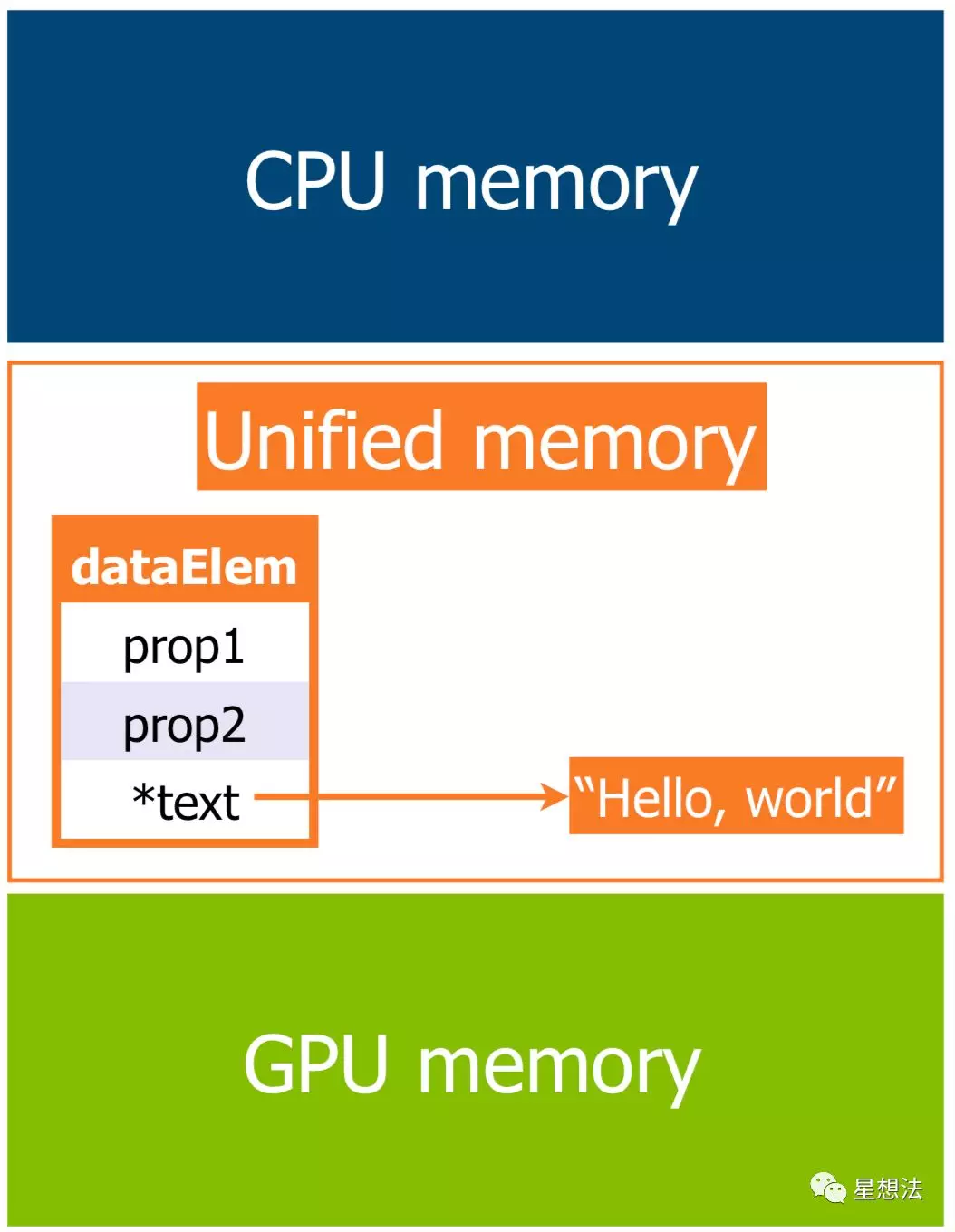
在引入Unified Memory之后,使用cudaMallocManaged函数分配统一的内存,无须多次内存的拷贝。
02cuda-fixnum代码库
cuda-fixnum是一个使用CUDA的支持大数计算的代码库,实现了大数的算术运算和模运算。目前支持的大数的长度是:32,64,128,256,512,1024和2048。cuda-fixnum也是学习cuda开发的非常好的示例。
https://github.com/data61/cuda-fixnum
cuda-fixnum代码库目录结构如下:
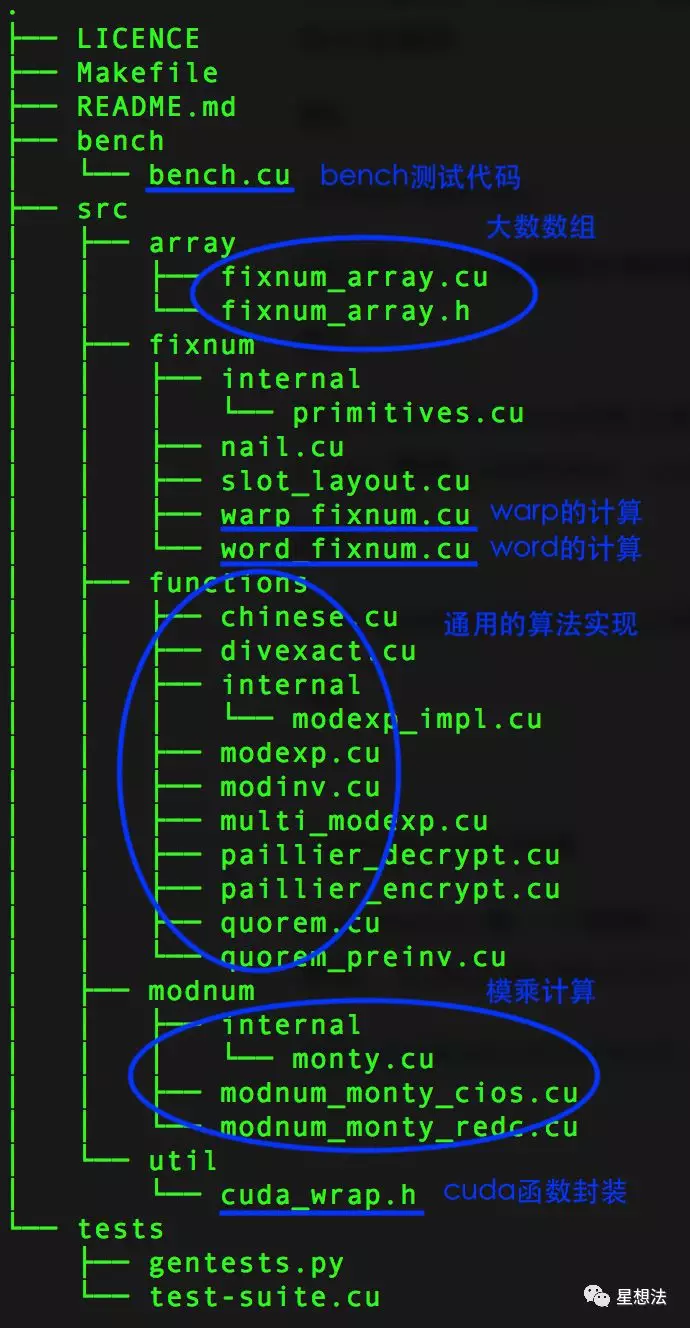
word_fixnum实现的是单个数(32bit或者64bit)的运算。warp_fixnum实现的是cuda线程执行模型下的大数的运算(加减乘除)。一个大数由多个数组成。注意的是,warp_fixnum对象本身也只是存储单个数,只是在cuda线程执行模型下,warp_fixnum通过cuda指令能操作同一个warp下的所有的数。也就是说,在一个warp中的Thread只处理一个单个数。modnum目录下实现了蒙特马利算法的大数模乘。cuda_warp.h是cuda函数的封装。
重点讲两个方面:1/ fixnum_array的kernel函数以及线程的设置 2/ warp_fixnum的mul_wide函数实现。
fixnum_array的kernel函数和线程
fixnum_array通过create函数实现大数的GPU/CPU的内存的申请。fixnum::BYTES说明单个数的字节长度。nelts表明一个大数中单个数的个数。通过cudaMallocMananged函数,申请大数的内存,并存储在fixnum_array的ptr指针中。
template
fixnum_array *
fixnum_array::create(size_t nelts) {
fixnum_array *a = new fixnum_array;
a->nelts = nelts;
if (nelts > 0) {
size_t nbytes = nelts * fixnum::BYTES;
cuda_malloc_managed(&a->ptr, nbytes);
}
return a;
}
ptr指针的定义在fixnum_array.h文件中:
fixnum *ptr;
注意的是,ptr定义为fixnum*的类型,而在内存申请时,只是申请的大数的内存。逻辑上就存在fixnum到单个数之间的转换(warp_fixnum提供转换函数):
private:
digit x;
// TODO: These should be private
public:
__device__ __forceinline__
operator digit () const { return x; }
__device__ __forceinline__
operator digit &() { return x; }
fixnum_array中map函数实现了GPU的函数调用:
template
template class Func, typename... Args >
void
fixnum_array::map(Args... args) {
// TODO: Set this to the number of threads on a single SM on the host GPU.
constexpr int BLOCK_SIZE = 192; //定义了Block Thread的最大个数
// FIXME: WARPSIZE should come from slot_layout
constexpr int WARPSIZE = 32; //一个Warp支持的Thread个数,一般都是32
// BLOCK_SIZE must be a multiple of warpSize
static_assert(!(BLOCK_SIZE % WARPSIZE),
"block size must be a multiple of warpSize");
int nelts = std::min( { args->length()... } );
constexpr int fixnums_per_block = BLOCK_SIZE / fixnum::SLOT_WIDTH; //一个Block能计算的大数的个数
// FIXME: nblocks could be too big for a single kernel call to handle
int nblocks = ceilquo(nelts, fixnums_per_block); //计算Block的个数
// nblocks > 0 iff nelts > 0
if (nblocks > 0) {
cudaStream_t stream;
cuda_check(cudaStreamCreate(&stream), "create stream");
// cuda_stream_attach_mem(stream, src->ptr);
// cuda_stream_attach_mem(stream, ptr);
cuda_check(cudaStreamSynchronize(stream), "stream sync");
dispatch>>(nelts, args->ptr...); //调用GPU进行Func的计算,指定Block/Thread个数以及Stream
cuda_check(cudaPeekAtLastError(), "kernel invocation/run");
cuda_check(cudaStreamSynchronize(stream), "stream sync");
cuda_check(cudaStreamDestroy(stream), "stream destroy");
// FIXME: Only synchronize when retrieving data from array
cuda_device_synchronize(); //等待GPU处理完成
}
}
一个Thread处理一个单个数,在给定一个Block能处理的最大Thread数,大数的个数的情况下,可以计算出需要的Block的个数。dispatch函数是kernel函数,会在GPU的SP(核)上运行。Stream是逻辑概念,用于Kernel的并行和同步。默认情况下,使用Stream 0。
dispatch函数逻辑相对简单,idx是大数的偏移量,off是单个数的偏移量。dispatch函数使用global函数前缀,表明dispatch函数是从Host端请求,在Device(GPU)上执行。每个Thread都会执行dispatch函数,也就是执行fn函数。fn函数有个特征,就是参数的类型相同。
template class Func, typename fixnum, typename... Args >
__global__ void
dispatch(int nelts, Args... args) {
// Get the slot index for the current thread.
int blk_tid_offset = blockDim.x * blockIdx.x;
int tid_in_blk = threadIdx.x;
int idx = (blk_tid_offset + tid_in_blk) / fixnum::SLOT_WIDTH; //计算出大数的偏移量
if (idx
// TODO: Find a way to load each argument into a register before passing
// it to fn, and then unpack the return values where they belong. This
// will guarantee that all operations happen on registers, rather than
// inadvertently operating on memory.
Func fn;
// TODO: This offset calculation is entwined with fixnum layout and so
// belongs somewhere else.
int off = idx * fixnum::layout::WIDTH + fixnum::layout::laneIdx();
// TODO: This is hiding a sin against memory aliasing / management /
// type-safety.
fn(args[off]...);
}
}
fn函数在bench/bench.cu中定义,mul_wide函数是其中一个函数,定义如下:
template
struct mul_wide {
__device__ void operator()(fixnum &r, fixnum a) {
fixnum rr, ss;
fixnum::mul_wide(ss, rr, a, a);
r = ss;
}
};
warp_fixnum的mul_wide函数
warp_fixnum的mul_wide函数实现了大数的乘法,代码实现了大数a乘以大数b,结果的高位部分在ss中,低位部分在rr变量中。
__device__ static void mul_wide(fixnum &ss, fixnum &rr, fixnum a, fixnum b) {
int L = layout::laneIdx();
fixnum r, s;
r = fixnum::zero();
s = fixnum::zero();
digit cy = digit::zero();
fixnum ai = get(a, 0);
digit::mul_lo(s, ai, b);
r = L == 0 ? s : r; // r[0] = s[0];
s = layout::shfl_down0(s, 1);
digit::mad_hi_cy(s, cy, ai, b, s);
for (int i = 1; i
fixnum ai = get(a, i);
digit::mad_lo_cc(s, ai, b, s);
fixnum s0 = get(s, 0);
r = (L == i) ? s0 : r; // r = s[0]
s = layout::shfl_down0(s, 1);
// TODO: Investigate whether deferring this carry resolution until
// after the loop improves performance much.
digit::addc_cc(s, s, cy); // add carry from prev digit
digit::addc(cy, 0, 0); // cy = CC.CF
digit::mad_hi_cy(s, cy, ai, b, s);
}
cy = layout::shfl_up0(cy, 1);
add(s, s, cy);
rr = r;
ss = s;
}
带有device前缀的函数,只能在GPU上执行。
假设大数a/b/rr/ss都是32个32bit的单数组成,也就是大数是32*32=1024位。在GPU上,mul_wide会发送给32个Thread,由一个Warp进行处理,每个Thread处理1个32bit的单数:

mul_wide的大数乘法的计算过程类似于小学学乘法使用的竖式计算过程:

通过一个大数中的每一个单数和另外一个大数相乘的结果相加,获得最终大数相乘的结果。注意每个单数和另外一个大数相乘的结果存在一定的“偏移”。仔细观察发现,从低到高,每个单数和大数相乘之后,最终结果的相应低位也确定。比如说1932*2=3864,最终大数乘积的最低位4也就确定。
mul_wide实现了相应的过程,可以简单把a想象成2142,b想象成1932。事实上,每个Thread处理的只是大数中的具体的每一个单数。在每个Thread中,要获取大数中的其他单数,使用get函数。比如get(a, 0)获取大数a中的第一个单数。
mul_wide每个单数和另外一个大数的乘积过程又分为三步:
第一步,计算每个单数的计算的低位:
fixnum ai = get(a, i); //获取a中指定的单数
digit::mad_lo_cc(s, ai, b, s); //单数和b中的单数相乘,乘积结果的低位,记录在s中
第二步,更新最终结果的相应的低位结果:
fixnum s0 = get(s, 0); //获取s中的第0个单数
r = (L == i) ? s0 : r; // r = s[0] //确定对应的低位的偏移
s = layout::shfl_down0(s, 1); //整个s,进行向右(低)移位(也就是把刚刚确定的单数移出去),为下面的计算做准备
第三步,更新每个单数和大数相乘的高位信息:
digit::mad_hi_cy(s, cy, ai, b, s);
因为在第二步中,s已经移位,所以在第三步中直接和计算结果相加即可。经过三步计算就能确定一个最低的单数和大数乘法的中间值。根据大数中单数的个数,循环计算过程,就能最终确定大数相乘的计算结果。
总结:
cuda是Nivdia GPU的一套编程框架,有一些术语:SM,SP,Grid,Block,Thread,Kernel等等。cuda-fixnum是开源的大数计算的cuda库,是学习cuda编程的好素材。
r424gwycftg.png

|








