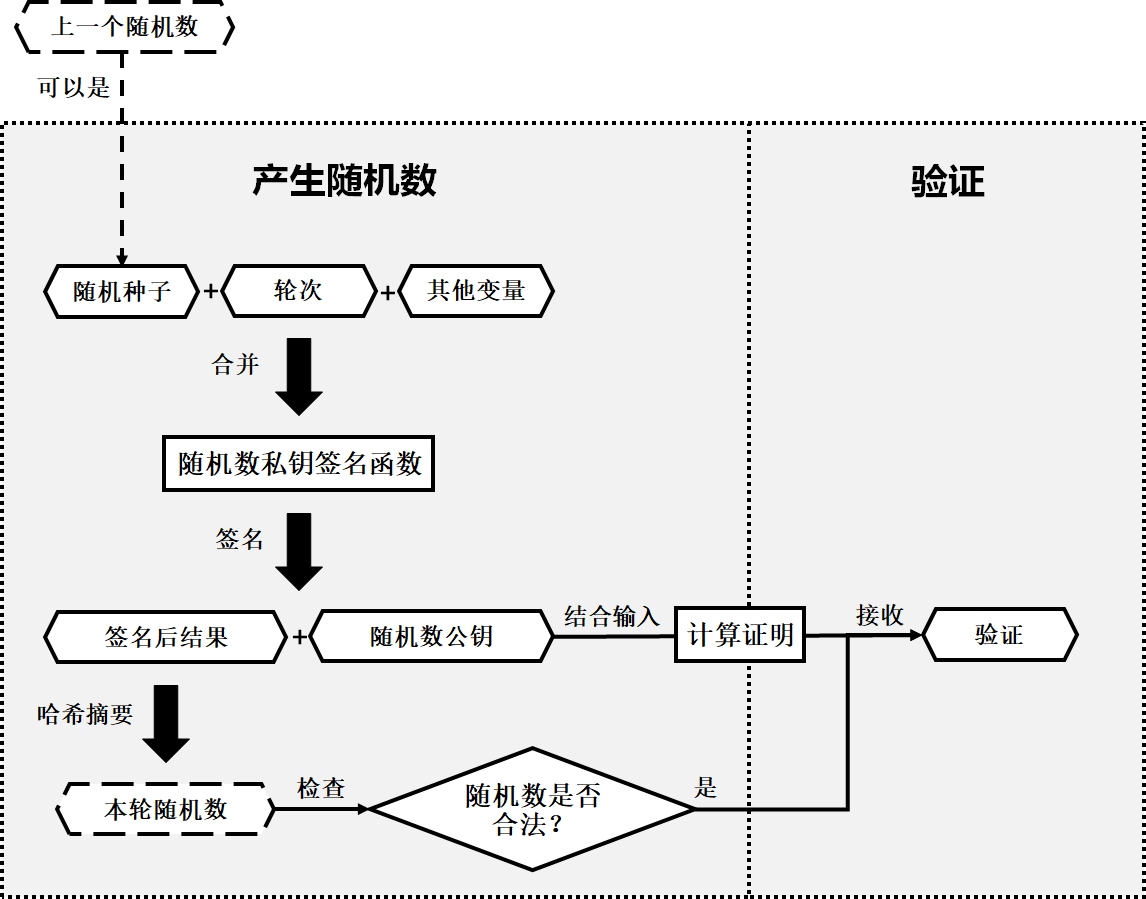
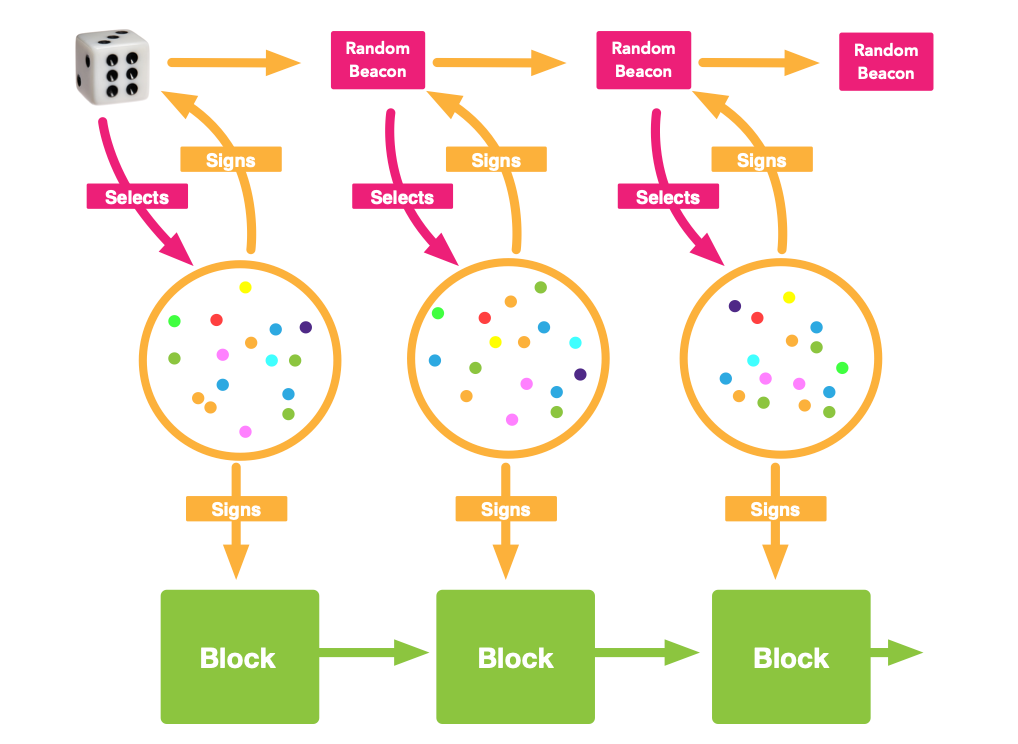
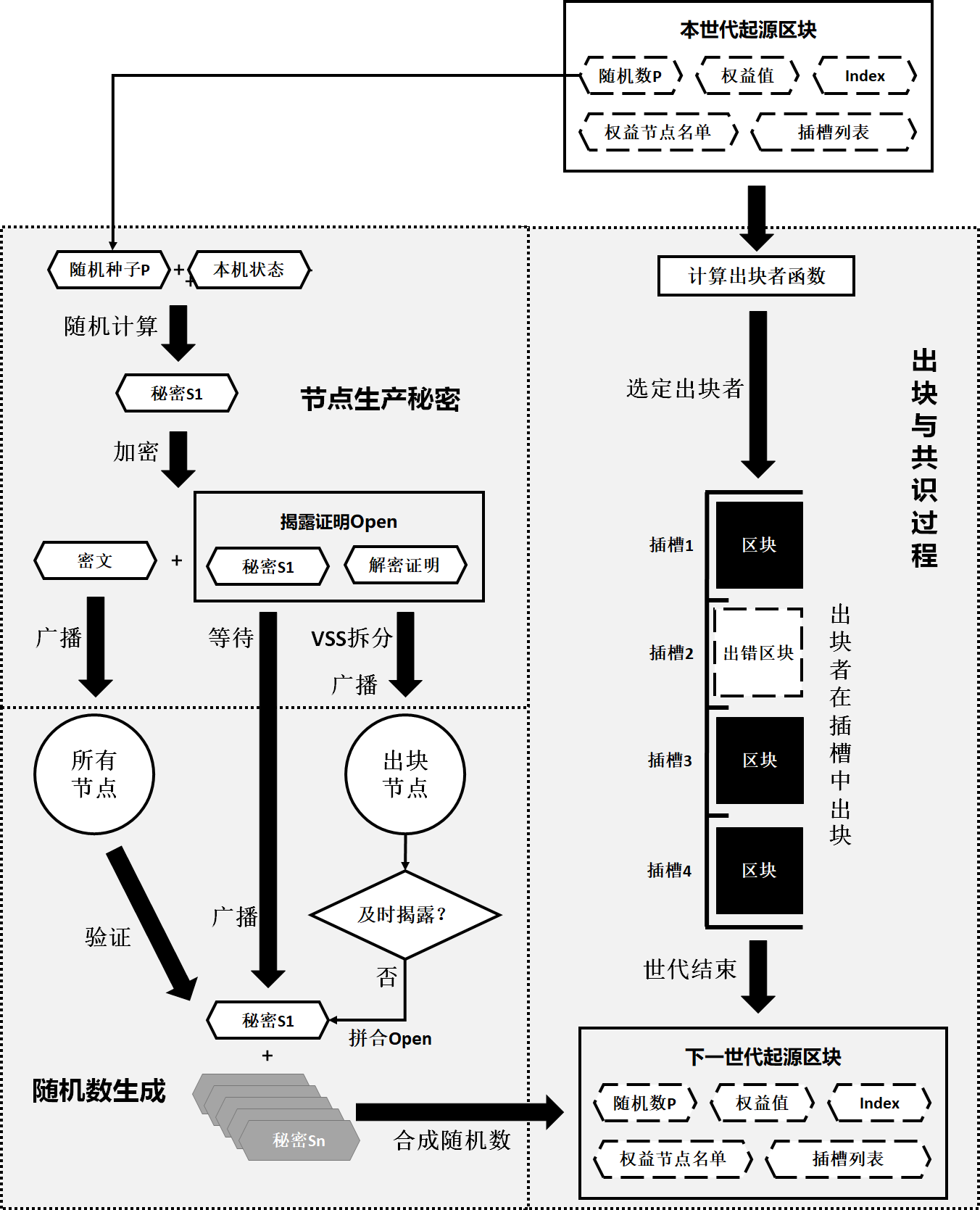
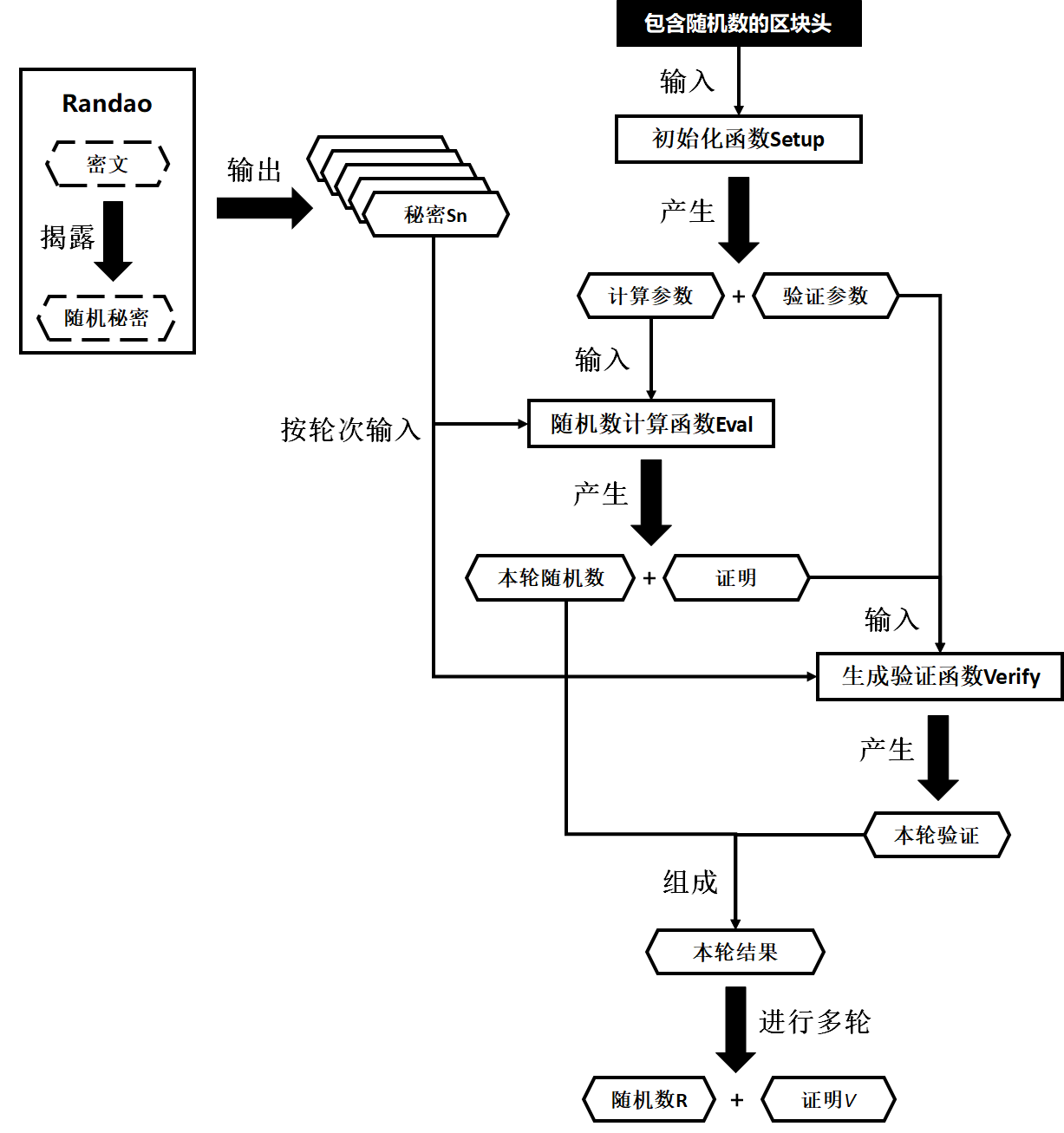
广播
动态
导读
淘帖
日志
相册
分享
记录
排行榜
帮助
20191115131045_NTW9.jpg
使用道具 举报
本版积分规则 发表回复 回帖并转播 回帖后跳转到最后一页
|Archiver|手机版|小黑屋|挖矿网
GMT+8, 2024-4-26 12:50
Powered by Discuz! X3.5
© 2001-2024 Discuz! Team|Designed by ThemeBox.